Visual DB (Semeion©)
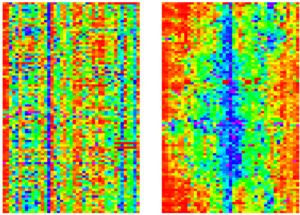
Given a “flat” dataset, i.e. rows (called records) x columns (the variables), randomly arranged, the goal of Visual DB algorithm is to minimize the sum of the differences between each cell of the data set and its first neighbors, by means row and column optimal permutation.
If we define the source dataset as a matrix, then we can argue that this matrix belongs to a universe of states of the all matrices generated by permuting its columns and its rows in all possible ways. We can also say that all matrices of this universe are equivalent to the source dataset from machine learning point of view.
The Visual DB algorithm relies on the assumption that existed between all these matrices a “optimal matrix”.
This optimal matrix is the matrix in which the sum of the square sum of differences between each cell and its nearest neighbors is smallest (considering the dataset as a toroidal topology).
Because the universe of all matrices that can be generated is very broad, it is necessary to use a heuristic tool to explore the universe of states.
The Visual DB algorithm is a bottom-up explorer, that at each iteration performs transformations on the source dataset in order to minimize the assigned cost function.
examples
Source Dataset →Optimal Matrix